Visualizing Insurance Fraud
Learn about fraud detection and how diagrams help to uncover fraud cases
What is Fraud Detection?
Fraud refers to the abuse of the assets of an organization, company, or person to make a profit. Many companies worldwide become victims of fraudsters even though most of them tend to believe that fraud is something that "could not happen to them". In general, most fraud cases are not being identified immediately, but only after remarkable damage has been caused. Unfortunately, this damage does not limit only on a severe economic loss but also invokes other liability issues towards clients, employees, financial institutions, and many other involved entities. Thus, it is fundamental to be able to identify fraud cases immediately and respond quickly.
Fraud detection refers to all the methods and techniques applied for the identification of potential fraud cases, their investigation to determine whether the identified cases are actual fraud cases or not, and the response to them. Unfortunately, there exist a lot of different fraud types and no unique mechanism that can identify all of them. Thus, auditors have to develop separate strategies to combat each type of fraud.
What is Insurance Fraud?
Insurance fraud occurs when the insurers intentionally raise "fake" insurance claims to gain insurance benefits to which they are not entitled. It also includes cases where a person denies to pay an insurance benefit that is due.
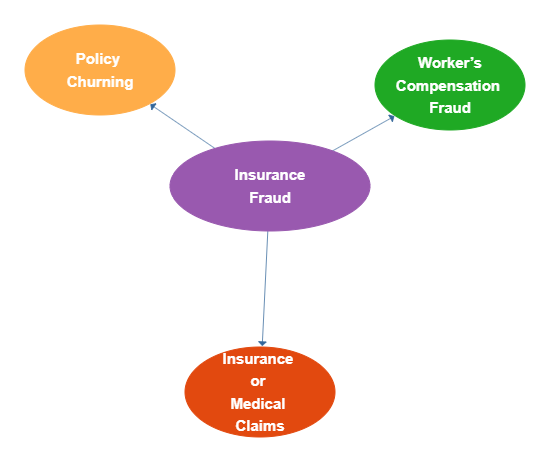
Insurance fraud can be classified based on its extent, either as "hard" or "soft". The first category refers to cases where a fraudster intentionally plans, causes, or fakes a loss to obtain reimbursement from the insurance company. This type of fraud includes, for example, a car accident, an auto theft, a fire, or even a fake death. In most cases, committing such a fraud requires more than one involved person. The second category refers to situations where the insurers claim from the insurance company reimbursements higher than the actual ones for services to which, however, they are entitled. For example, they claim more damages or more severe injuries in a car accident or state that the property stolen during a theft costs more than its actual cost. Fraud cases of this category tend to be more frequent and usually are unplanned.
Calculating the loss caused by insurance fraud is quite difficult since most of the cases are never identified. However, certain insurance fraud types like health care fraud affect not only the insurance companies themselves, but the society in total since the loss of the insurance companies is passed on to all their insured clients. It is hence, fundamental to be able to identify this fraudulent activity as soon as possible.
Why Use Visualizations for Insurance Fraud Detection?
The detection of insurance fraud schemes requires an investigation of a vast amount of data that stems from many different anti-fraud systems with varying types of data. The auditors have to combine all these data and use statistical methods to uncover suspicious claims, which in most cases, is time-consuming and inefficient.
Visualizations, on the other hand, can enhance the quick identification of relationships and significant structures. Suspicious patterns that may hide in this amount of data an be easily detected. Ideally, the auditors can also interact with the visualization, view the stored data, or even explore the dependency of the data with the time that they happened.
A typical pattern to look for is the so-called fraud ring, i.e., several persons that are (all or a part of them) involved in more than one series of events. For example, in a quite common insurance fraud scenario, auditors look for potential fraud rings. For this case scenario, fraud cases can be easier detected through the visualization rather than when trying to dig into a large number of database raws.
Challenges of Using Visualizations for Insurance Fraud Detection
One of the most challenging tasks when using visualization for fraud detection is the sheer amount of data that is usually obtained by auditing systems. First, the auditor has to retrieve the data from the auditing system.

Visualizing such a large amount of data is the next challenge: the data needs a meaningful arrangement to create a human-readable representation. Providing suitable styling should enable users to identify different types of entities and relations.
Furthermore, high performance is essential to allow for interactive exploration of the data utilizing the benefits of graph database visualization.
How to Create Visualizations for Insurance Fraud Fraud Detection?
A typical insurance fraud scenario involves fraudsters that stage fake car accidents and require reimbursement from the insurance companies for small injuries and damages that cannot be confirmed quickly by the insurance companies. Such scenarios may involve some or all passengers of the involved cars, the witnesses of the accidents, doctors, or lawyers.
This scenario involves the same persons that participate in the same series of accidents playing a different role each time, e.g., a person can appear one time as the driver of an involved car, another time as a witness of another car accident, and other times as a passenger. In such cases, also, the fraudsters can share the same lawyer and/or doctor who will confirm the accident.
Building such a visualization from scratch can be a challenging task. However, developers can save a lot of money, time, and workforce by using a software library that provides ready-to-use components for this task.
yFiles for HTML is a commercial programming library designed explicitly for diagram visualization and is a perfect fit for the challenges of fraud detection. The sophisticated layout algorithms of yFiles can comfortably transform the data in a readable, pleasing, and informative network. The different layout styles enable the user to intuitively identify structural characteristics of the data, such as cycles, connected components, or hierarchies.
Insurance Fraud Detection Application using yFiles for HTML
yFiles for HTML comes with a Fraud Detection Sample Application. It provides a visualization of time-dependent data for the detection of insurance fraud. The example consists of three different parts: the main diagram, the timeline component, and the details component.
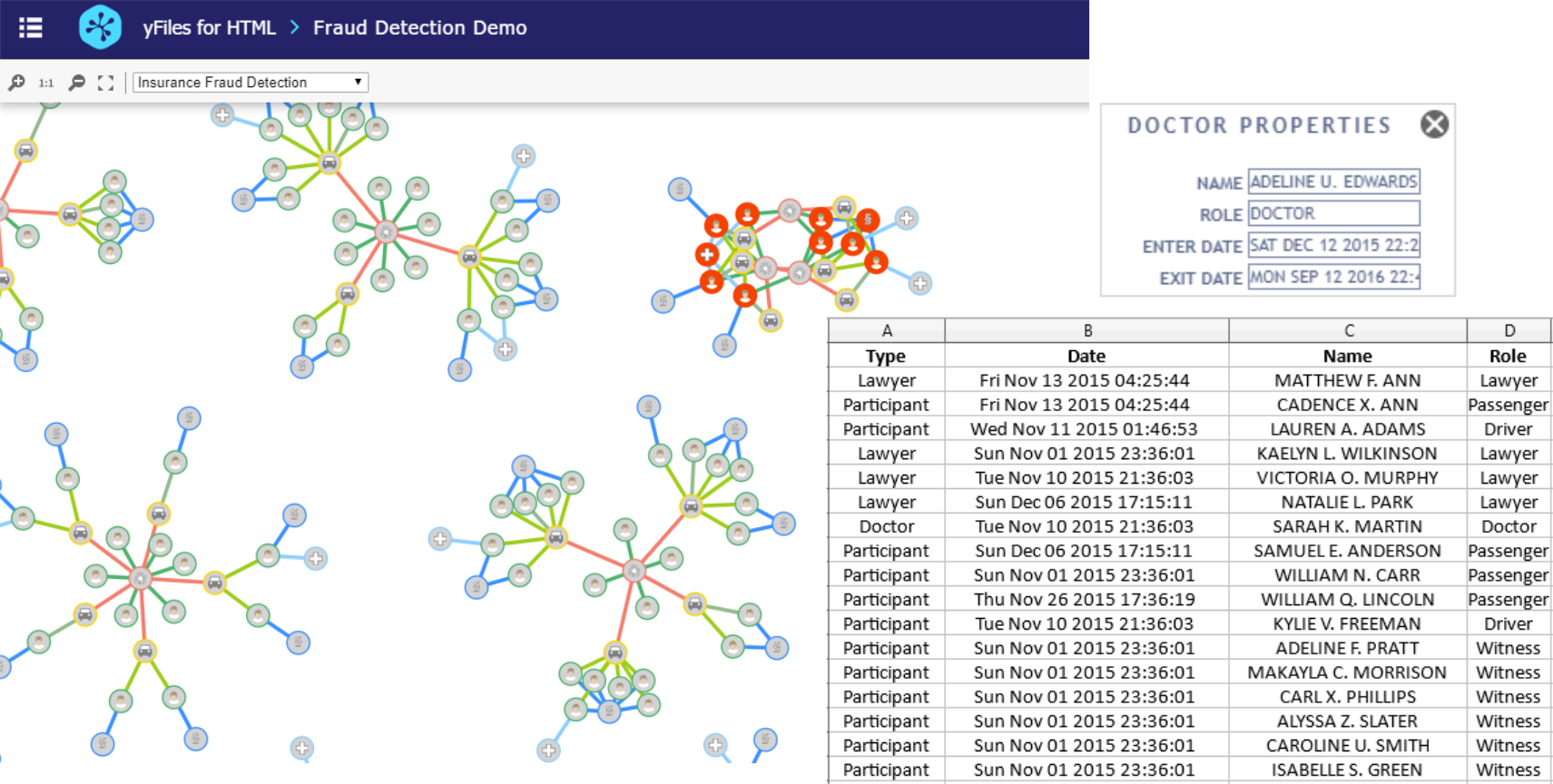
The Main Diagram
Each node of the main graph visualization represents a type of data like accident, driver, passenger, witness, lawyer, or doctor. The node types are easily distinguishable due to different visualization styles, using the flexible diagram visualization capabilities of yFiles for HTML. All nodes are also associated with two timestamps, one for their creation and one for their removal. For example, when a node represents a person, the first timestamp refers to the first event in which this person is involved, while the second refers to the last event. Based on these two timestamps, the nodes are filtered and appear in the main visualization only within a specific time interval.
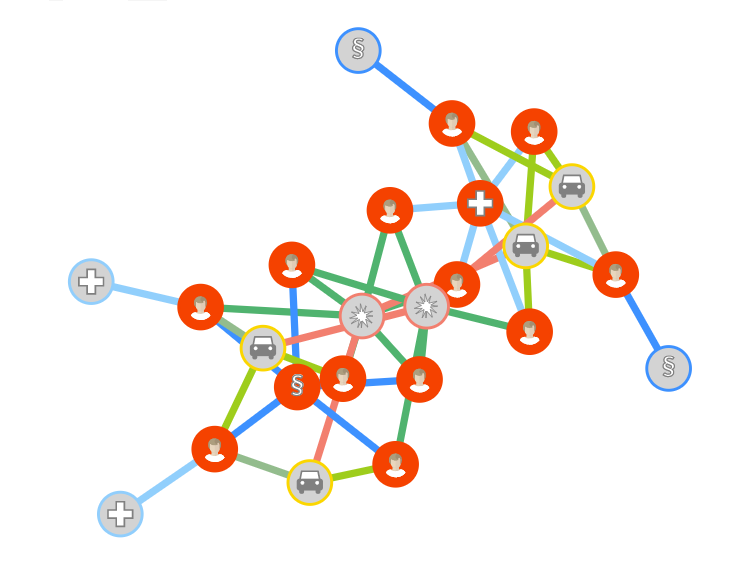
Edges connect the accidents to the involved car and the witnesses. Each person in a car has a role, i.e., driver or passenger, and is connected to a car and optionally to a lawyer or a doctor.
The edges represent the relationship between the nodes that connect and have different colors based on their type. Namely, there are six types of relations:
-
a car is involved in an accident
-
a person witnesses an accident
-
the driver drives a car,
-
a person is a passenger of a car
-
a lawyer represents a person (driver/passenger/witness)
-
a doctor heals a person (driver/passenger/witness)

The main window also comes with a fraud detection mechanism that highlights the nodes that may be involved in a potential fraud ring with a red color. Thus, the auditor can distinguish possible fraud rings at a glance and investigate them further. A popup menu is provided to display the properties of each node and facilitate the investigation. The fraud rings are directed using the graph analysis capabilities of yFiles for HTML.
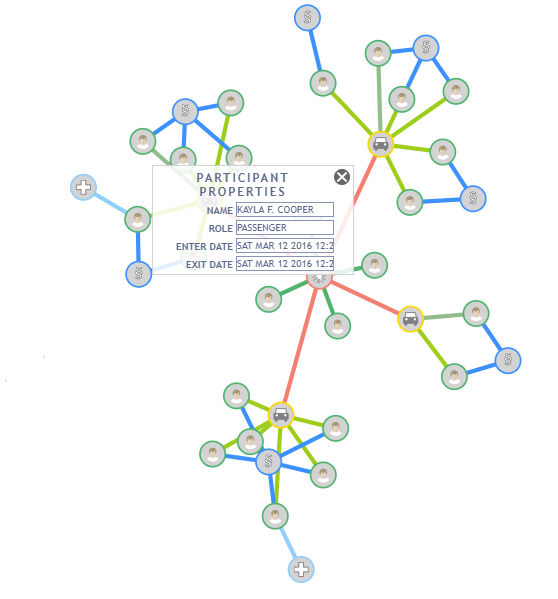
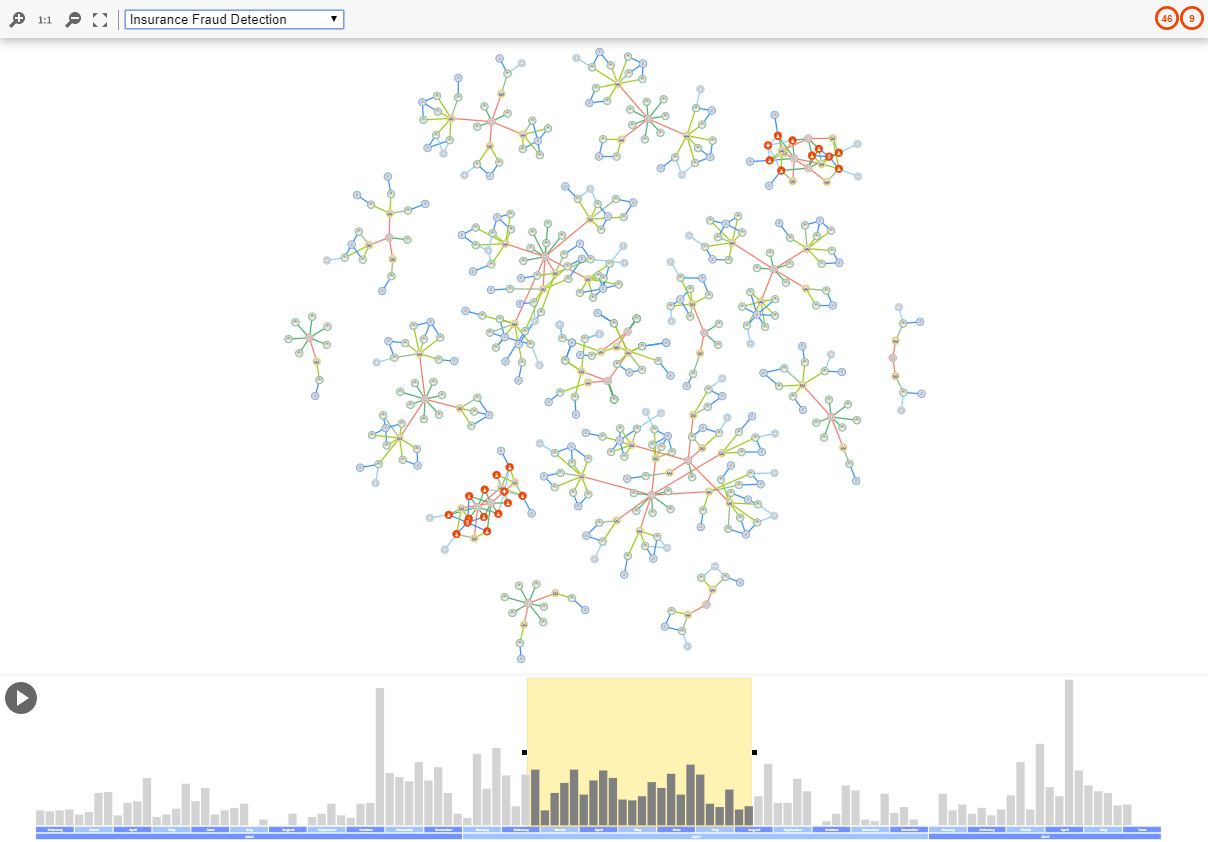
The Timeline Component
The timeline component is built upon the time-dependent data of the main graph visualization. It shows the overall number of creation and removal events with a bar for each timestamp. It is also equipped with a time-frame rectangle to select the time interval that is important for the user. This time-frame is resizable and can be dragged to fit the user’s needs. Based on the selected time interval, the nodes of the graph are filtered so that only the ones whose time interval overlap with the chosen time interval are visible in the graph. In this manner, the main visualization remains uncluttered, and the user can focus only on the currently visible elements.
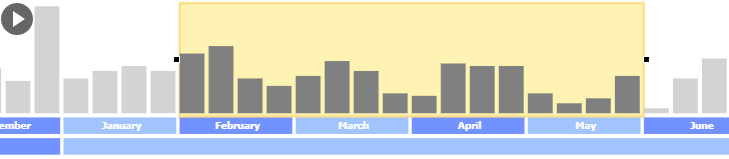
The timeline component provides a video button that automatically moves the time-frame to the right while updating the main graph. In this manner, the auditor can obtain an overall view of the dataset while it is also possible to stop the video when a fraud ring is detected to investigate it further and determine whether this refers to an actual fraud case.
During the movement of the time-frame, the graph structure evolves, i.e., new nodes and edges are added in the visualization while other elements disappear. One of the most critical challenges with an evolving graph is to adapt the visualization to these graph changes. For example, new graph elements have to be arranged, and, after node removals, the remaining graph elements have to be re-arranged. However, these operations need to keep the overall picture of the graph, the so-called mental map, stable to save the user from getting confused.
This example application uses an algorithm for the node arrangement that adapts possible graph changes. Algorithms that arrange elements in a diagram or, as they might also be called, automatic layout algorithms are one of the key features of yFiles for HTML.
To facilitate the investigation, both the main graph visualization and the timeline component can coordinate: when a node in the main graph is highlighted/selected, the corresponding timestamps of the timeline component are highlighted/selected and vice-versa.
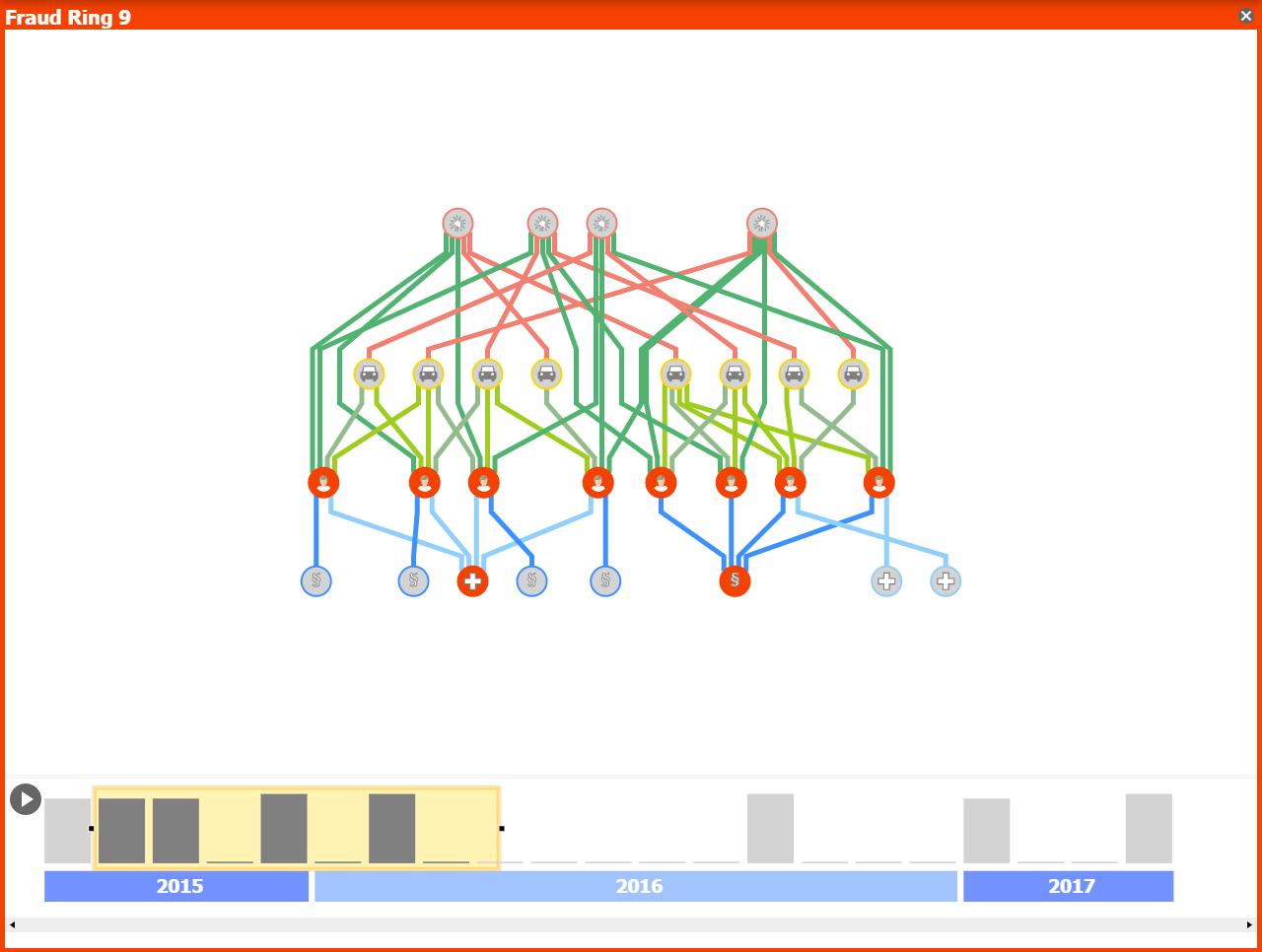
The Details Component
When a fraud ring is detected, the auditor can switch to the detailed view with a timeline component, which displays a snapshot of the graph that contains only the nodes involved in the fraud ring. With this additional filtering operation, the auditor can focus only on the fraud ring without being distracted by the remaining graph elements that have no relation with the potential fraud component.
Examples Source Code
With yFiles, fraud detection diagrams can be realized on all supported platforms. The source code of the Fraud Detection Sample Application that comes with yFiles for HTML is available on the yWorks GitHub repository and part of the yFiles for HTML package.