| Concepts | ||
|---|---|---|
| Prev | Chapter 5. Automatic Graph Layout | Next |
This page is from the outdated yFiles for Java 2.13 documentation. You can find the most up-to-date documentation for all yFiles products on the yFiles documentation overview page.
Please see the following links for more information about the yFiles product family of diagramming programming libraries and corresponding yFiles products for modern web apps, for cross-platform Java(FX) applications, and for applications for the Microsoft .NET environment.
The task of a layout algorithm is a major undertaking that involves arbitrarily complex logic. However, there can be identified a number of well-defined (sub-)tasks that even completely different algorithms do in a similar manner. Factoring out such tasks so that they can be reused in varying contexts, greatly reduces the complexity of any layout algorithm.
The yFiles library allows to formulate complex layout processes by plugging together so-called "layout stages" that, among other things, can be used to handle such well-defined (sub-)tasks.
A layout stage serves as a kind of container that encapsulates arbitrary layout
functionality, and provides a general means to string together multiple stages
into a compound layout process.
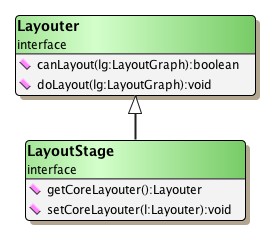
Interface LayoutStage![]() defines the
basis for a layout stage.
It is a specialization of interface
Layouter
defines the
basis for a layout stage.
It is a specialization of interface
Layouter![]() , and thus can be used as a
stand-alone layout provider as well as a part of a larger layout process.
, and thus can be used as a
stand-alone layout provider as well as a part of a larger layout process.
The methods of interface LayoutStage are used to establish a relationship to another Layouter implementation, the so-called "core layouter." The core layouter's invocation is entirely bracketed by the layout stage's logic.
When used in the context of a larger layout process, the layout stage can easily be used to simplify the core layouter's task. It performs preprocessing steps on the input graph before the core layouter's invocation, and postprocessing steps thereafter.
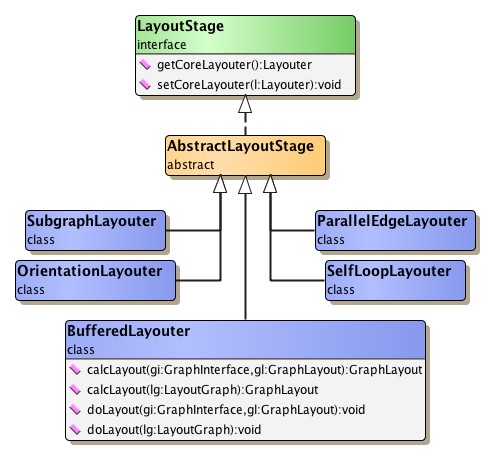
Table 5.1, “Predefined layout stages” lists some of the predefined LayoutStage implementations, most of them being part of the default compound layout process as described below. Further layout stages are described in the section called “Layout Stages”.
Table 5.1. Predefined layout stages
| Classname | Description |
|---|---|
| BufferedLayouter |
Duplicates the graph to be processed, so that the layout cannot destroy the original data. See also the description of buffered layout calculation below. |
| SelfLoopLayouter |
Calculates orthogonal edge paths for a graph's self-loops (reflexive edges). |
| ParallelEdgeLayouter |
Calculates edge paths for all edges with identical source node and target node. (Self-loops are not processed.) |
| OrientationLayouter |
Changes the orientation of a computed layout. |
| SubgraphLayouter |
Reduces the original graph to the subgraph that is induced by selected nodes. |
Figure 5.7, “Layout stages complex” shows the class hierarchy for the layout stages.
Except for class BufferedLayouter, all layout stages from Table 5.1, “Predefined layout stages” are part of the compound layout process defined by CanonicMultiStageLayouter. The following methods of class CanonicMultiStageLayouter can be used for configuring the layout process:
void appendStage(LayoutStage stage) |
|
| Description | Methods to add and remove individual layout stages. |
void enableOnlyCore() |
|
| Description | Methods for enabling and disabling the predefined layout stages, and also for controlling their enabled state. (Excerpt.) |
LayoutStage getComponentLayouter() |
|
| Description | Getter and setter methods for predefined layout stages. (Excerpt.) |
With the yFiles layout algorithms it is possible to have a graph layout
calculated using two different approaches, namely "unbuffered" layout or
"buffered" layout.
Unbuffered layout means to directly invoke a layout algorithm's
doLayout![]() method.
Choosing this approach, the layout calculation is performed on the given graph,
and is also immediately assigned.
Buffered layout, in contrast, utilizes class
BufferedLayouter
method.
Choosing this approach, the layout calculation is performed on the given graph,
and is also immediately assigned.
Buffered layout, in contrast, utilizes class
BufferedLayouter![]() , which creates a copy
of the original graph that is then used for layout calculation.
, which creates a copy
of the original graph that is then used for layout calculation.
Unbuffered layout has some severe drawbacks that should be observed:
With these drawbacks in mind, it is almost always a good idea to choose buffered layout instead. It facilitates many sophisticated features, like, e.g., layout morphing, and at the same time increases an application's robustness.
The main purpose of class
BufferedLayouter![]() is to create a copy of
the input graph before calling its core layouter.
The graph structure that is used for the copied graph is optimized for layout
calculation.
is to create a copy of
the input graph before calling its core layouter.
The graph structure that is used for the copied graph is optimized for layout
calculation.
The core layouter subsequently executes on the copy and calculates a new layout, which is then transferred to the original graph. There are several beneficial aspects of this functionality:
Wrapping a layout algorithm with a BufferedLayouter layout stage is as easy as shown in Example 5.3, “Using buffered layout”.
Example 5.3. Using buffered layout
// 'graph' is of type y.layout.LayoutGraph. // Run organic layout by implicitly wrapping its invocation using the services // of class BufferedLayouter. new BufferedLayouter(new SmartOrganicLayouter()).doLayout(graph);
Alternatively, class BufferedLayouter allows to get the calculated graph layout as a separate object. This is demonstrated in Example 5.4, “Buffered layout with deferred coordinate assignment”.
Example 5.4. Buffered layout with deferred coordinate assignment
// 'graph' is of type y.layout.LayoutGraph.
// Run organic layout by implicitly wrapping its invocation using the services
// of class BufferedLayouter.
// The result of the layout is returned separately as a GraphLayout object,
// i.e., the original graph's layout information is not changed.
GraphLayout gl =
new BufferedLayouter(new SmartOrganicLayouter()).calcLayout(graph);
The yFiles layout algorithms support advanced functionality that can take into account even individual information for single graph elements. However, individual setup like, e.g., attaching a preferred edge length to each edge, is beyond the means a graph structure provides. Instead, the data accessor concept as described in the section called “Binding Data to Graph Elements” is utilized to provide the individual setup as supplemental information to a layout algorithm.
The supplemental data for the graph elements is bound to the graph using a so-called "data provider key." During layout calculation, the algorithm then retrieves the data provider that contains the data from the graph by using the same key.
Depending on the data provider key, the algorithm expects the returned data provider to hold values of specific type for either nodes or edges of the graph. Example 5.5, “Binding supplemental data” shows the use of an implicit data provider that returns an integral value for each edge indicating the edge's preferred length to the organic layout algorithm.
Example 5.5. Binding supplemental data
// 'graph' is of type y.layout.LayoutGraph.
// Create an implicit data provider and register it with the graph using a
// so-called data provider look-up key.
// The key is then used by the layout algorithm to retrieve the supplemental
// data.
graph.addDataProvider(SmartOrganicLayouter.PREFERRED_EDGE_LENGTH_DATA,
new DataProviderAdapter() {
public int getInt(Object o) {
return (int)(200 * getLength((Edge)o));
}
});
// Invoke organic layout on the graph.
SmartOrganicLayouter sol = new SmartOrganicLayouter();
sol.doLayout(graph);
// Remove the data provider from the graph.
graph.removeDataProvider(SmartOrganicLayouter.PREFERRED_EDGE_LENGTH_DATA);
Class AbortHandler![]() provides an abort mechanism
for layout calculations.
This mechanism can be used to trigger early termination as well as instant termination
of a layout calculation.
provides an abort mechanism
for layout calculations.
This mechanism can be used to trigger early termination as well as instant termination
of a layout calculation.
The abort handler for a graph is specified through a data provider that is bound
to the graph.
The data provider is expected to be registered with the graph using key
ABORT_HANDLER_DPKEY![]() .
Once an abort handler is attached to a graph, any layout algorithm with support
for the abort mechanism working on this graph can be stopped or canceled using the
abort handler's methods.
.
Once an abort handler is attached to a graph, any layout algorithm with support
for the abort mechanism working on this graph can be stopped or canceled using the
abort handler's methods.
AbortHandler createForGraph(Graph graph) |
|
| Description | Returns a graph's attached abort handler or creates a new one and attaches it. |
void stop() |
|
| Description | Methods to trigger termination of layout calculations. |
Stopping the layout calculation results in early, but not immediate, termination where the layout algorithm still delivers a consistent result.
Canceling, in contrast, will end layout calculation instantly, throwing an AlgorithmAbortedException and all work done so far by the algorithm will be discarded. This may lead to an inconsistent state of the graph. It is thus recommended to only cancel layout algorithms that work on a copy of the graph to avoid corrupting the original graph.
Furthermore, when layout calculation is ended instantly, the state of the Layouter instance may become corrupted. Hence, a new instance has to be created after each cancelation.
If a graph that has an AbortHandler attached is processed by multiple layout algorithms (or multiple times by one layout algorithm), then the attached handler has to be reset between algorithm runs:
void reset() |
|
| Description | Resets the abort handler's state so that any requests for early termination are discarded. |
Otherwise, previous requests for early termination may lead to an undesired early termination of a subsequent algorithm run.
The following code skeleton outlines the conceptual sequence of AbortHandler calls around a layout calculation:
Example 5.6. Using an abort handler in conjunction with a layout calculation
// 'graph' is of type y.base.Graph. // First retrieve the abort handler that is attached to the graph. AbortHandler handler = AbortHandler.createForGraph(graph); // Reset the abort handler to avoid early termination due to previous stop or // cancel requests. handler.reset(); // Start layout calculation here. // ... // Now the layout algorithm can be stopped... handler.stop(); // ... or canceled, if desired. handler.cancel();
The following layout algorithms and routing algorithms of the yFiles library have built-in support for the abort mechanism:
Table 5.2. Support for abort mechanism in yFiles algorithms
| Classname | |
|---|---|
| Layout algorithms | IncrementalHierarchicLayouter |
| CircularLayouter |
|
| SmartOrganicLayouter |
|
| OrthogonalLayouter |
|
| Layout stages | ComponentLayouter |
| ParallelEdgeLayouter |
|
| Routing algorithms | EdgeRouter |
Tutorial demo application Graph2DLayoutExecutorDemo.java shows how to create and use an abort handler when layout calculation is performed by class Graph2DLayoutExecutor.
The multi-threading support that is used by the algorithms in the yFiles library can reduce the runtime of a layout calculation. The support is based on the underlying threading capabilities of the Java Runtime Environment (JRE) and exploits the provided resources of multi-core processor architectures.
Multi-threaded layout calculation is enabled per algorithm by means of a simple boolean setter method. It can readily be used in any algorithm that provides support for it and doesn't need any special setup.
The key role in this multi-threading support has abstract class TaskExecutorFactory![]() .
Implementations of this class are responsible for creating so-called task executors
that handle and run the single tasks that a layout calculation needs to be split
into to take full advantage of multiple threads of execution.
.
Implementations of this class are responsible for creating so-called task executors
that handle and run the single tasks that a layout calculation needs to be split
into to take full advantage of multiple threads of execution.
The default implementation of this factory class doesn't create task executors itself,
but instead dynamically delegates this duty to another, actual factory, which it
finds by a multi-step search procedure.
The first step in this search queries the
Java service registry
to find an implementation of the TaskExecutorFactory class.
By default, this yields class MultiThreadedTaskExecutorFactory![]() ,
which is listed with its fully-qualified name:
,
which is listed with its fully-qualified name:
y.util.MultiThreadedTaskExecutorFactory
in the service declaration file META-INF/services/y.util.TaskExecutorFactory in the META-INF directory of the yFiles for Java library Jar file.
As described in the online Java Tutorials, this setup enables Creating Extensible Applications, where customized behavior can be achieved without altering an application's source code. Simply by adding a new Jar file to an application's class path that contains
the underlying multi-threading support can be adjusted to instantly take into account the most elaborated processor architectures or scheduling requirements at a customer's site.
The fully-qualified class name contained in the service declaration file and in the name of the service declaration file itself need to match the classes' names in the Jar file also after the obfuscation process. To this end, an additional <adjust> element needs to be used in the yGuard Ant script to obfuscate your yFiles for Java-powered application. The additional <adjust> element is presented in Example A.2, “Using the yGuard Ant task”.
Similar adjustments to the fully-qualified class names need to be applied to any separate Jar files that contain custom service declarations for the service defined by the TaskExecutorFactory class.
The following layout algorithms of the yFiles library have built-in support for multi-threaded layout calculation:
Table 5.3. Support for multi-threaded layout calculation in yFiles algorithms
| Layout Style | Classname | Note |
|---|---|---|
| Organic | SmartOrganicLayouter |
See the algorithm execution options of class SmartOrganicLayouter. |
|
Copyright ©2004-2016, yWorks GmbH. All rights reserved. |