
Visualizing Database Relationships
Gain insights about your database relationships through diagram visualizations
A database is a collection of arbitrary data that ranges from small, manually depicted data sets to vast collections of automatically compiled data. It can be loosely connected (e.g., a relational database) or focused on relationships (e.g., a graph database) between entities.
With growing size and complexity, databases quickly become an experts’ domain such that only a few users understand what the database contains and how to change or extend it. The restriction to only tech-savvy persons can limit the usefulness of a database or needs in-depth instruction on handling the data.
An interactive application that visualizes the content of the database can help in this scenario.
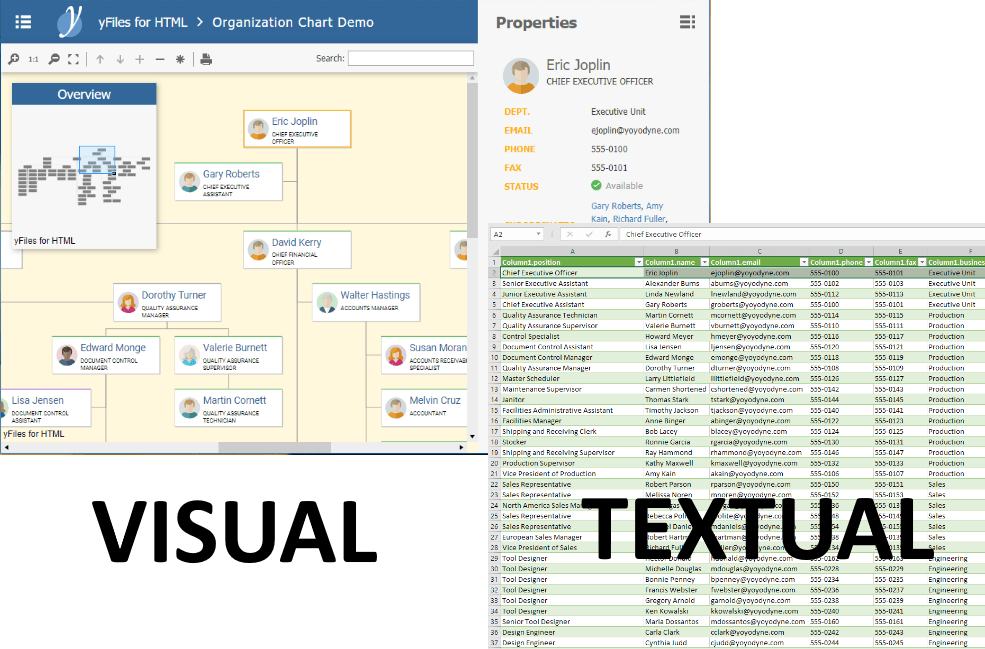
It enables users to visually explore the stored data, identify significant structures, and get a better understanding of relationships. Besides the visual exploration, it is also possible to interactively edit the stored data by modifying the diagram without any in-depth knowledge of the underlying storage technology.
Challenges of Database Visualization
A database visualization is most useful when the entities form actual relationships. Although such data is predestined for visualization, it is still a challenging task because of the sheer amount of data that it usually contains.
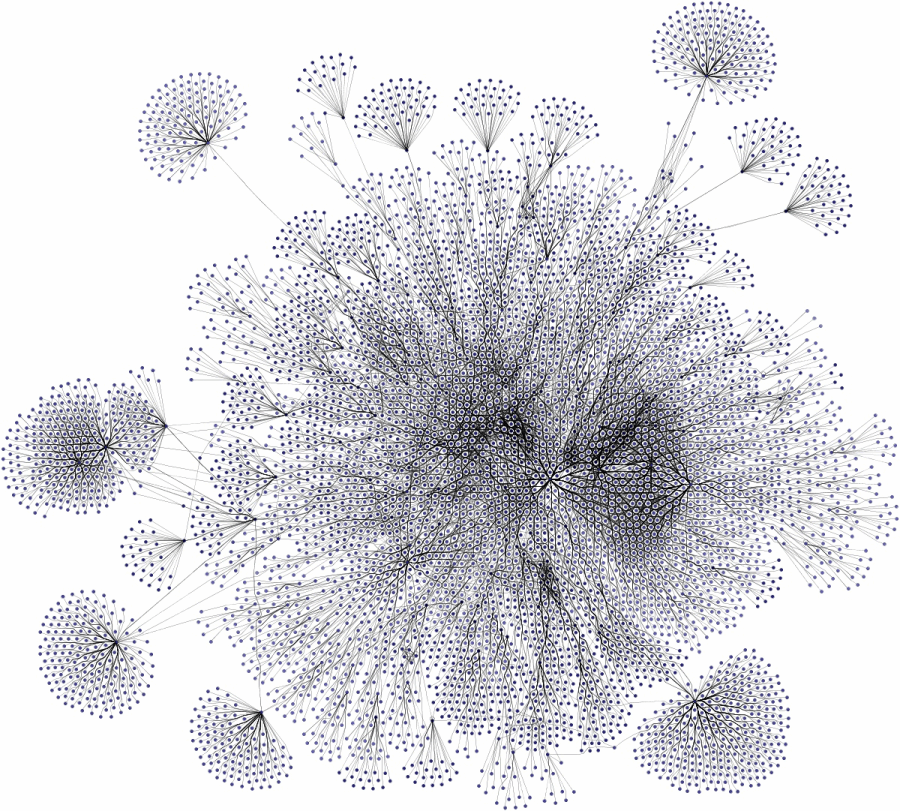
The first step in presenting the data is to query it from the database. After that, the query result must be arranged meaningfully to create a human-readable representation of the raw data. Additionally, a styling that differentiates the different types of entities and relations and presents the properties associated with the items helps to interpret the data at a glance. Furthermore, the performance should allow for an interactive exploration of the data.
Visualizing the Database Content
A graphical representation of the stored data can be beneficial because it emphasizes the connection of the data and therefore reveals specific structures and makes it easy to explore the database. Many databases provide a basic visualization of the stored data through their particular client applications. These graphical representations usually allow the user to only see local parts of the stored entities and relations alongside associated properties. Some data explorers also provide the means to edit the stored data in their graphical user interface.
However, the built-in explorers are often limited in the amount of data they can display at once, or they provide only a relatively simple representation and interaction. Sometimes it is required to tailor the visualization, user interaction, and automatic layout of the data for a specific use case, which is not possible with the built-in solutions, or the database does not come with any graphical representation at all.
Visualizing the Database Schema
The database schema defines the database structure and the stored entities in a formal language.
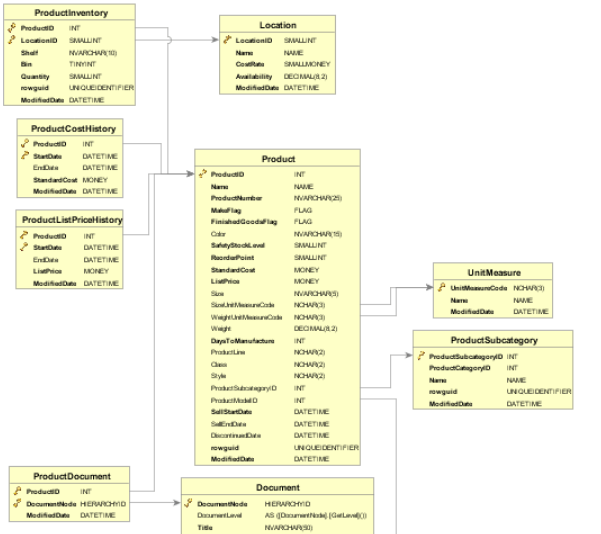
Visualizing the schema is a useful tool when designing and maintaining the database. It clearly states the relationships and associated entities such that obscure or unnecessary connections are easily visible. An interactive representation may even enable non-technical users to modify the database and add new entities.
Utilizing a Sophisticated Visualization Solution
A comprehensive visualization solution provides a means to create a client that enables users to gain more insight into the stored data. It can be tailored to specific requirements related to element visualization, element arrangement, or interactions.
yFiles is a commercial programming library explicitly designed for diagram visualization and is a perfect fit for the challenges of database visualization. The sophisticated layout algorithms of yFiles can easily transform the data in a readable, pleasing, and informative network. The different layout styles, for example, hierarchic, organic, tree, circular or radial, enable the user to intuitively identify structural characteristics of the data, such as hierarchy, connected components, or rings.
Furthermore, yFiles comes with a multiplicity of graph analysis algorithms (e.g., centrality, clustering, path algorithms, etc.) that can be applied to the data model to add more value to the data.
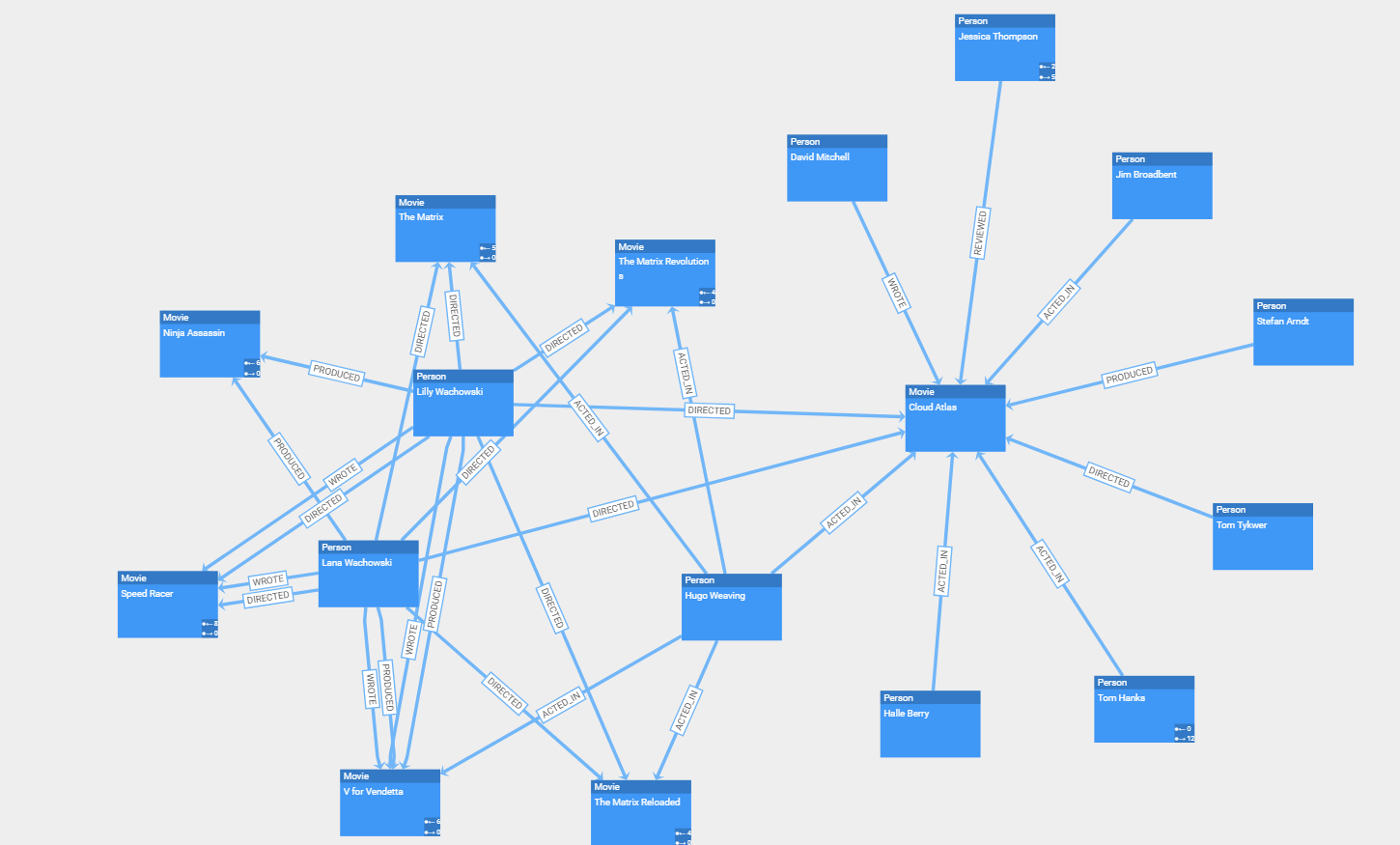 |
 |
 |
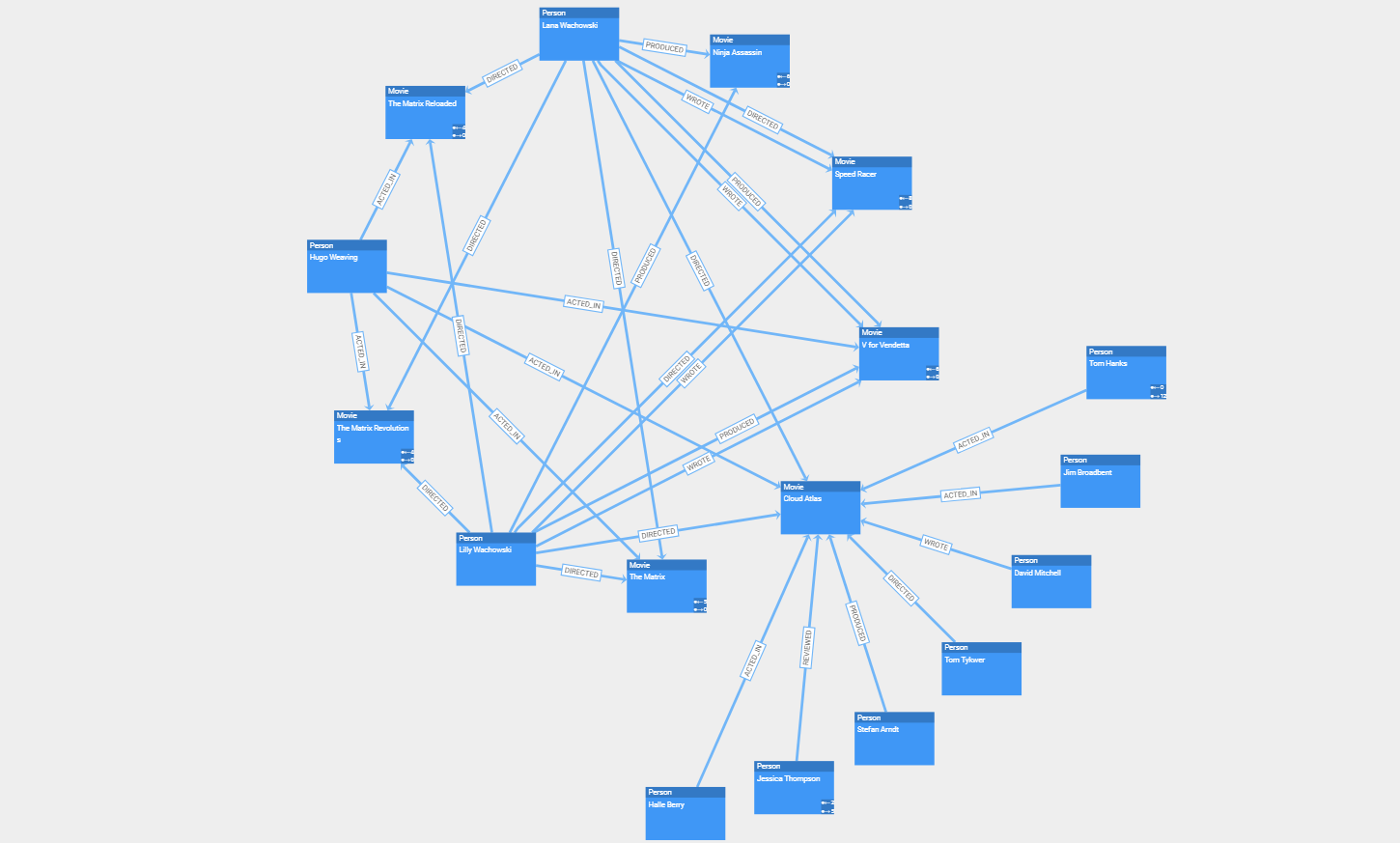 |
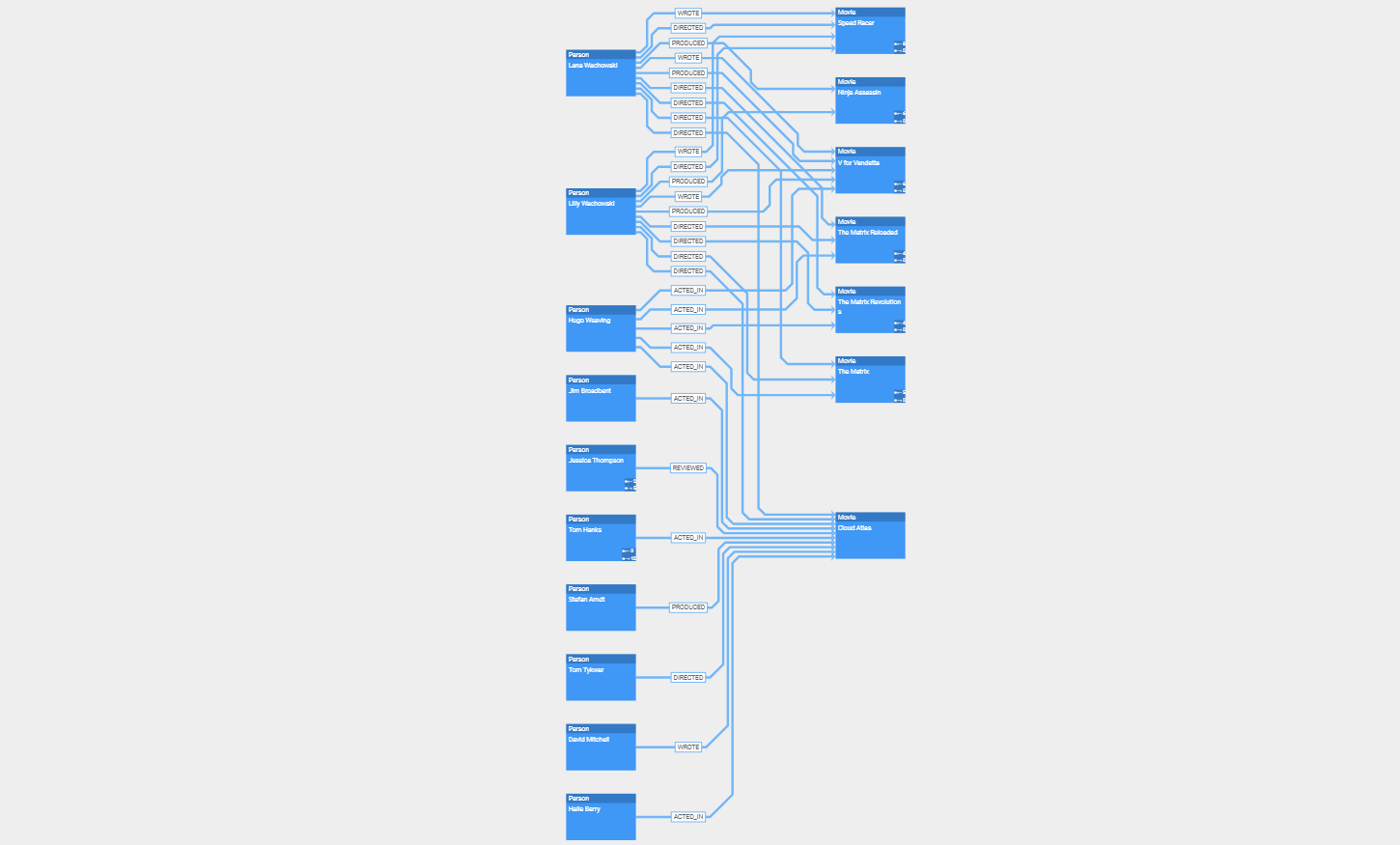
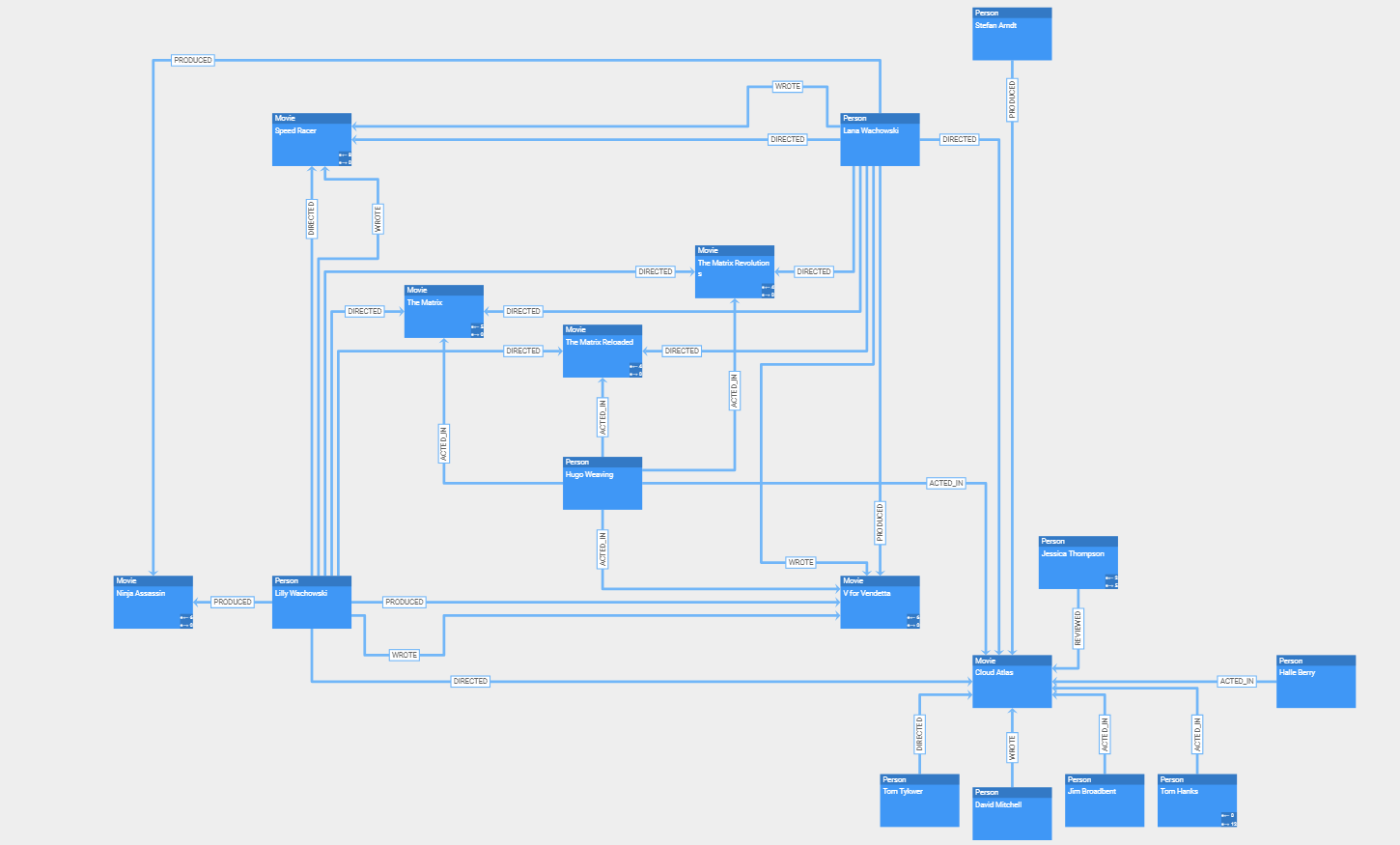
In a neatly arranged diagram, users can easily navigate and edit the relationships and data objects with the powerful interaction handling that yFiles provides out of the box. The library is also fully customizable and extensible to support scenarios where interactive drill-down exploration is needed to focus the user’s attention on local parts of a huge diagram.
The relationships and data objects can be rendered using the node and edge styles that come with yFiles, which already offer a wide range of properties to tailor the style for a particular use case or branding. If this is not sufficient, it is always possible to create an entirely custom visualization that perfectly fits the given data.
Which Data Sources Can Be Used?
Usually, databases are accessed with query languages like SQL to extract information from them, each yielding data in a slightly different format. A generic data interface can be connected to arbitrary data sources to transform the different query results into a graph model.
This generic approach allows yFiles to augment any database, for example, Oracle, MySQL, Microsoft SQL Server.
Webinar: How to Visualize Database Content with yFiles
The Visualizing Your Neo4j Database Contents like a Pro! webinar explains how to visualize a Neo4j database with yFiles for HTML in a simple web application built with JavaScript:
This information is also available in the blog post Visualizing Neo4j Database Contents Like a Pro.
Examples and Source Code
yFiles for HTML comes with a Neo4j Sample Application and a GraphQL Sample Application that show how to load data from a Neo4j database and a GraphQL service, respectively.
The source code of these sample applications is part of the yFiles for HTML package and available on the yWorks GitHub repository: