Products
Downloads
Demos
RSS Newsfeed
All Articles
Posts labeled "
Hackathon
"
2020-2-4
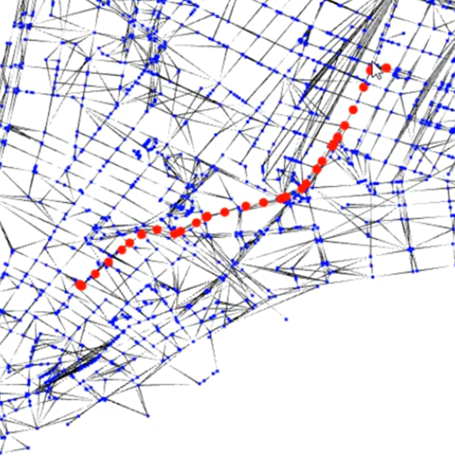
Hackathon at Stackoverflow Offices
During the GraphConnect 2018, we took part in a hackathon all around Neo4j at the offices of Stack Overflow and helped to build a Manhattan-based geospatial data visualization.
All Articles
Latest Blog Posts
Working with Graphs in Augmented - and Virtual-Reality
RobyGraph Cosmic Graph Strategy
From Experiments to Agents: How yWorks Uses AI to Democratize Graph Visualization
Making AI-generated diagrams useful and interactive
Enabling LLM development through knowledge graph visualization
Use Cases
Business process management
Company structures
Data management
Supply chain management
Test and experience
yFiles free
of charge!
Free support
Fully functional
100+ source-code examples
Try now